Key takeaways
- ChatGPT now averages 8.5 fan-out queries per prompt -- four times what it used to -- and each query has roughly doubled in word count since October 2025.
- Width (how many sub-queries fire) determines whether your brand gets a chance to appear at all. Depth (how specific each sub-query gets) determines whether you actually win the citation.
- 95% of fan-out phrases show zero monthly search volume in traditional keyword tools, which means conventional SEO research misses almost all of them.
- Depth is becoming the more decisive dimension in 2026, as ChatGPT 5.5 issues longer, more precise sub-queries rather than simply more of them.
- The practical fix is a combination of topical breadth (to capture width) and tightly scoped, focused pages (to win on depth) -- not long-form "ultimate guides."
When someone asks ChatGPT "what's the best project management software for remote engineering teams," they type one sentence. What happens next is invisible to them but very visible to the brands competing for that answer: ChatGPT fires off somewhere between 6 and 12 parallel search queries before it writes a single word of its response.
This is query fan-out. And understanding it is now one of the most important things a marketing team can do.
But here's the part that most guides gloss over: fan-out isn't one-dimensional. There are two distinct axes to think about -- width (how many sub-queries the model generates) and depth (how specific and long each individual sub-query gets). These two dimensions have different implications for brand visibility, and optimizing for one without understanding the other is a good way to waste a lot of content budget.
So which one matters more? Let's work through it properly.
What fan-out width and depth actually mean
Before getting into strategy, it's worth being precise about the terms, because they get conflated.
Fan-out width is the number of sub-queries ChatGPT generates from a single user prompt. If you ask about CRM software for startups, the model might fire off queries for "best CRM for startups 2026," "CRM pricing comparison small business," "HubSpot vs Salesforce for startups," "CRM free tier options," and "startup CRM reviews Reddit" -- all at once, in parallel. That's a width of five.
Fan-out depth is how specific and granular each individual sub-query is. A shallow sub-query might be "project management tools." A deep one might be "project management software for distributed engineering teams with Jira integration under $20 per user." Same topic, very different retrieval behavior.
These two dimensions interact, but they're driven by different things and they reward different content strategies.
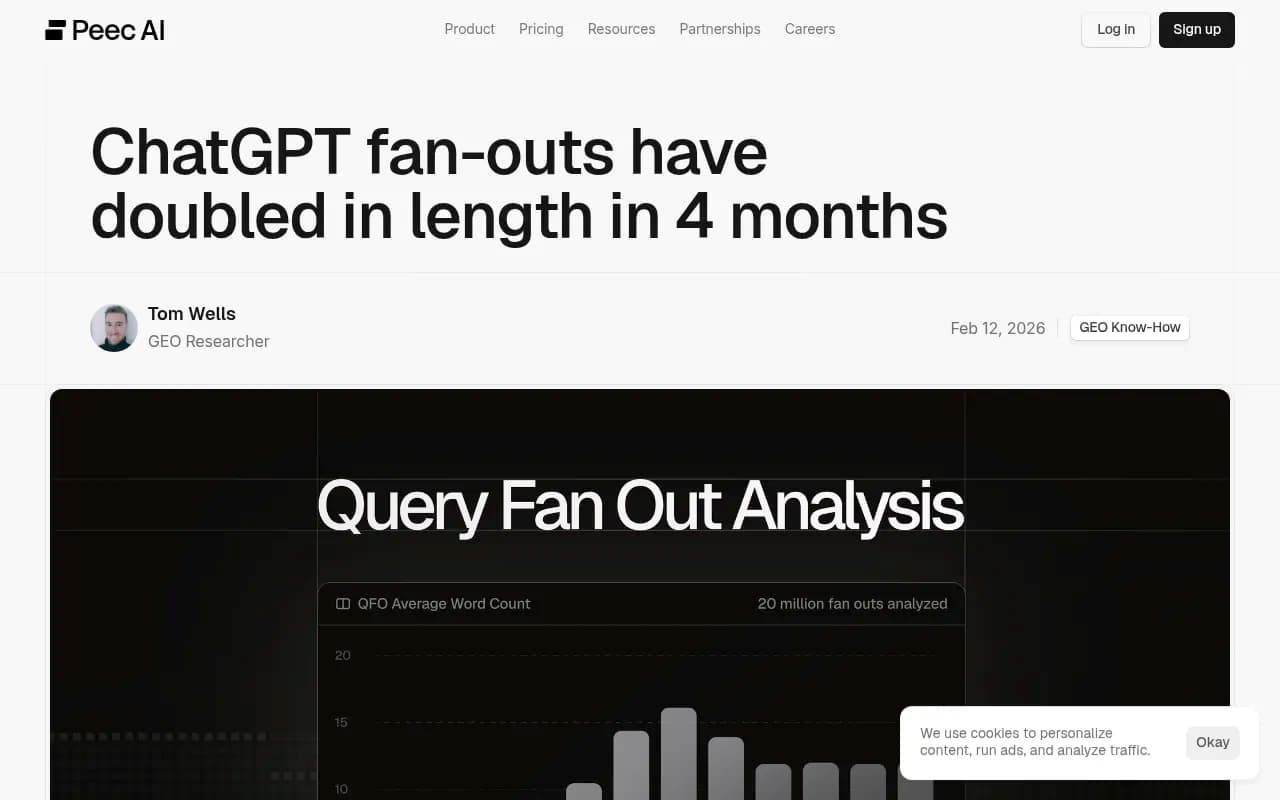
The numbers behind the shift
The data here is striking. Analysis of 20 million ChatGPT fan-out queries by Peec AI found that the average word count per sub-query roughly doubled from October 2025 to January 2026 -- rising from around 6 words to around 12, with a peak of 16 words around week 49. That's a depth explosion.
Meanwhile, the number of sub-queries per prompt (width) has stayed relatively stable since early 2026. ChatGPT isn't firing more queries -- it's making each query more precise.
Separately, data from a large-scale analysis of 72,000+ AI-generated queries across 8,700+ prompts (cited by 85SIXTY's SEO team) found that ChatGPT and Gemini routinely trigger 8 to 10 parallel sub-queries per prompt. Chris Long noted on LinkedIn that ChatGPT is now averaging 8.5 fan-out queries -- roughly four times its earlier average of 2.
So the picture in mid-2026 looks like this: width has already expanded dramatically and plateaued, while depth is still actively growing. That has real implications for where to focus.
Why width still matters (but is table stakes now)
Width determines whether your brand is even in the game. If ChatGPT generates 8 sub-queries on a topic and your site only has content relevant to 2 of them, you're invisible for the other 6. Those 6 queries will surface competitors, Reddit threads, review sites, and YouTube videos instead.
This is why topical coverage -- having content that addresses a topic from multiple angles -- remains foundational. Think of it like a net: the wider your net, the more sub-queries you can catch. If you only publish one page about your product category, you're fishing with a hook.
The practical implication is that brands need content that covers:
- Comparison angles ("X vs Y", "alternatives to X")
- Pricing and cost queries ("how much does X cost", "X pricing for small teams")
- Review and trust signals ("X reviews", "X complaints", "X limitations")
- Use-case specific angles ("X for e-commerce", "X for agencies")
- Freshness signals (dated content, recent updates, 2025/2026 references)
95% of fan-out phrases show zero monthly search volume in traditional keyword tools. That's the 85SIXTY finding, and it's the reason keyword research alone will not get you there. The sub-queries ChatGPT generates don't look like search queries -- they're more like research questions a diligent analyst would ask.
Width is now table stakes for any brand that wants to appear in AI answers. But it's not the differentiator it was 18 months ago, because the model's width has stabilized. The real competition is happening on depth.
Why depth is becoming the decisive dimension
Here's what's changed: as ChatGPT's sub-queries get longer and more specific, the sources that get retrieved change. A 6-word query might surface a category page or a homepage. A 16-word query is going to surface a very specific piece of content -- or nothing useful at all.
This is where the "ultimate guide" strategy starts to break down. Kevin Indig's analysis of 815,000 query-page pairs found that shorter, focused content consistently outperforms long-form comprehensive guides for ChatGPT citations. The model isn't looking for the page that covers everything -- it's looking for the page that answers this specific question precisely.
A 3,000-word guide that covers 15 subtopics will lose to a 600-word page that answers one specific question cleanly, every time a deep fan-out sub-query fires for that specific question.
This is counterintuitive if you've spent years in traditional SEO, where longer content with more keyword coverage generally won. In AI search, depth of focus beats breadth of coverage at the page level. You need breadth at the site level (width) and focus at the page level (depth).
The ChatGPT 5.5 analysis from Seer Interactive reinforces this: the model's fan-out patterns show a clear preference for brand-specific, entity-rich content. When sub-queries get long and specific, they often include brand names, specific features, or named comparisons. If your content doesn't contain those specific entities, it won't be retrieved.
The interaction between width and depth
Width and depth aren't independent. They interact in a way that creates a specific content architecture challenge.
Think of it as a tree. Width is how many branches the tree has. Depth is how long each branch grows. To capture visibility across the whole tree, you need:
- Enough branches (topical coverage across the category)
- Each branch long enough to reach the specific sub-queries (focused, precise pages)
A site with 50 thin pages covering 50 topics has width but no depth. A site with one 10,000-word guide has depth on one branch but no width. Neither wins consistently.
The brands that are winning in AI search in 2026 are building what you might call a hub-and-spoke content architecture, but with a twist: the spokes need to be more specific than most teams are used to writing. Not "CRM for startups" as a spoke -- but "CRM for seed-stage SaaS startups with under 10 salespeople" as a spoke. That's the depth the model is now querying for.
What this means for content strategy
A few concrete implications:
The answer gap is your starting point. Before writing anything, you need to know which sub-queries are firing in your category and which ones your content is missing. This is what answer gap analysis tools are built for. Promptwatch does this specifically -- it shows you which prompts competitors are being cited for that you're not, then maps that to the specific content gaps on your site.

Focused pages beat comprehensive guides for depth. If you're creating content to win deep fan-out sub-queries, write one page per specific question. Don't bundle five related questions into one article. The model will retrieve the focused page for the specific question and ignore the bundled one.
Topical breadth still matters for width. You still need coverage across the category. The mistake is thinking that one or two pillar pages will do it. They won't -- not when the model is generating 8+ sub-queries per prompt, most of which are looking for something more specific than a pillar page covers.
Freshness signals matter more than most people realize. The 85SIXTY data found that "2024 2025" appears in 6% of all fan-out queries. The model is actively looking for recent content. Dated content that hasn't been updated will lose to fresher content on the same topic, even if the older content is more comprehensive.
Entity and brand specificity matters for depth. As sub-queries get longer, they get more entity-rich. Your content needs to contain the specific brand names, product names, and comparison terms that appear in those long-tail sub-queries. Generic category content won't be retrieved for a 16-word sub-query asking about a specific use case.
Tracking which dimension you're winning on
This is where most teams get stuck. Traditional rank tracking tells you nothing about fan-out performance. You can't see which sub-queries are firing, which ones you're being retrieved for, or which ones are converting into final citations.
To actually measure this, you need visibility at the prompt level and the page level -- which pages are being cited, for which prompts, by which models. You also need to understand query fan-out structure: how many sub-queries a given prompt generates, what they look like, and where your content sits in the retrieval chain.
Tools like Promptwatch track this at the page level and show you the path from crawl to citation. That's the data you need to understand whether you're winning on width (appearing across many prompts) or depth (being the cited source for specific, precise sub-queries).
A few other tools worth knowing about for different parts of this problem:
For tracking AI visibility across models:
For content optimization toward specific sub-queries:
A practical framework for 2026
Here's how to think about prioritization given where things stand:
| Dimension | What it determines | Current trend | Priority |
|---|---|---|---|
| Width (sub-query count) | Whether you appear at all | Stable at ~8.5 per prompt | Foundation -- must have |
| Depth (sub-query specificity) | Whether you win the citation | Still growing (word count doubling) | Differentiator -- where to compete |
| Freshness | Whether you're retrieved over older content | Consistently important | Ongoing maintenance |
| Entity richness | Whether deep queries retrieve your page | Increasingly important with depth | Build into every page |
| Page focus | Whether a specific page wins a specific sub-query | Focused pages outperform guides | Content architecture decision |
The practical priority order for a brand starting from scratch:
- Map the fan-out landscape for your category -- what sub-queries are actually firing?
- Audit your current coverage -- which sub-queries do you have content for, and which are gaps?
- Build topical width first -- make sure you have at least some content for each major sub-query cluster.
- Then go deep on the highest-value sub-queries -- create focused, specific pages that answer one question precisely.
- Track page-level citations to see which pages are being retrieved and which aren't.
- Iterate: update thin pages, add entity specificity, refresh dates.
The honest answer to the question
Depth is winning in 2026. Not because width doesn't matter -- it does, and you can't ignore it -- but because the competitive frontier has shifted. Most brands with any content investment have already achieved some degree of topical width. The gap that's opening up now is in depth: the brands creating focused, entity-rich, precisely scoped pages for long-tail sub-queries are the ones getting cited.
The doubling of fan-out word count since October 2025 is the signal. ChatGPT isn't casting a wider net -- it's using a finer one. Your content needs to be fine enough to get caught in it.
That means fewer "ultimate guides" and more tightly scoped pages. It means content architecture that prioritizes specificity over comprehensiveness at the page level. And it means tracking fan-out performance, not just traditional rankings, to know whether what you're publishing is actually being retrieved.
The brands that figure this out in the next six months will have a meaningful advantage. The ones that keep publishing broad pillar content and hoping for the best will find themselves increasingly invisible in AI answers -- even if their traditional SEO metrics look fine.